Lawsuits against artificial intelligence tools created by Stability AI, Midjourney, and DeviantArt
 A lawsuit has been filed against Stable Diffusion, a 21st-century collage tool that infringes on artists’ rights, on the grounds that artificial intelligence (AI) should be fair and ethical for all.
A lawsuit has been filed against Stable Diffusion, a 21st-century collage tool that infringes on artists’ rights, on the grounds that artificial intelligence (AI) should be fair and ethical for all.
After all, concern about the violation of AI rights by writers, artists, programmers and other creators is growing every day around the world. AI quickly learns on a huge number of copyrighted works, without the consent of the authors and without compensation for the use of rights.
A class action lawsuit has been filed on behalf of three amazing artist plaintiffs – Sarah Andersen, Kelly McKernan and Carla Ortiz – against Stability AI, DeviantArt and Midjourney for using Stable Diffusion, a 21st century collage tool that remixes the copyrighted works of millions of artists. whose works were used as training data.
Stable Diffusion is an artificial intelligence (AI) software product released in August 2022 by Stability AI. Stable Diffusion contains unauthorized copies of millions – and possibly billions – of copyrighted images. These copies were made without the knowledge or consent of the authors.
Even assuming nominal damages of $1 per image, the value of this misappropriation would be approximately $5 billion. (For comparison, the largest art theft in history was the theft of 13 works from the Isabella Stewart Gardner Museum in 1990, now valued at $500 million.)
Stable Diffusion belongs to the category of artificial intelligence systems called generative AI. These systems are trained on a specific type of creative work – such as text, software code, or images – and then remix those works to produce (or “generate”) more works of the same type.
 After copying five billion images – without the consent of the authors – Stable Diffusion uses the mathematical process of diffusion to store compressed copies of these training images, which in turn are recombined to produce other images. In short, it’s a 21st century collage maker.
After copying five billion images – without the consent of the authors – Stable Diffusion uses the mathematical process of diffusion to store compressed copies of these training images, which in turn are recombined to produce other images. In short, it’s a 21st century collage maker.
The resulting images may or may not look like the training images. However, they are derived from copies of training images and compete with them in the market. At a minimum, Stable Diffusion’s ability to flood the market with virtually unlimited infringing images will cause irreparable harm to the art market and artists
Even Stability AI CEO Emad Mostak predicts that “future (AI) models will be fully licensed.” But Stable Diffusion is not like that. It is a parasite that, if allowed to multiply, will cause irreparable harm to artists now and in the future.
The diffusion method was invented in 2015 by AI researchers from Stanford University. The diagram below, taken from the Stanford team’s research, shows the two phases of the diffusion process using spiral-shaped training data.
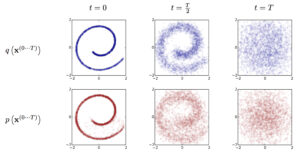 The first stage of diffusion is that we take an image (or other data) and gradually add more visual noise to it in several steps. (This process is depicted in the top row of the diagram.) At each step, the AI records how adding noise changes the image. At the last step, the image “disperses” in almost random noise.
The first stage of diffusion is that we take an image (or other data) and gradually add more visual noise to it in several steps. (This process is depicted in the top row of the diagram.) At each step, the AI records how adding noise changes the image. At the last step, the image “disperses” in almost random noise.
The second stage is similar to the first, but in reverse order. (This process is depicted in the bottom row of the diagram, which reads from right to left.) After capturing the steps that turn a certain image into noise, the AI can reverse those steps. Starting with random noise, the AI applies the steps in reverse order. By removing noise (or “de-noising”) the data, AI creates a copy of the original image.
In the diagram, the reconstructed spiral (in red) has some fuzzy parts in the lower half that are not present in the original spiral (in blue). Although the red spiral is simply a copy of the blue spiral, in computer terminology it is called a lossy copy, meaning that some details are lost in translation. This applies to many digital data formats, including MP3 and JPEG, which also produce highly compressed copies of digital data, omitting fine details.
In short, diffusion is how an AI program figures out how to reconstruct a copy of the training data using denoising. Since this is the case, from a copyright perspective it is no different from MP3 or JPEG – a way of storing a compressed copy of certain digital data.
 Remember the names of companies and services that, in our opinion, will be at the center of copyright infringement scandals more than once, if they do not change their attitude and algorithm operation policy. It’s simple – combine the payment of royalties to authors and the work of AI, and then it will be a great example for the combination and implementation of human and artificial. Because the author is still at the heart of the invention of the work.
Remember the names of companies and services that, in our opinion, will be at the center of copyright infringement scandals more than once, if they do not change their attitude and algorithm operation policy. It’s simple – combine the payment of royalties to authors and the work of AI, and then it will be a great example for the combination and implementation of human and artificial. Because the author is still at the heart of the invention of the work.
Stability AI
Founded by Emad Mostak, Stability AI is based in London.
Stability AI is funded by LAION, a German organization that creates ever-larger datasets of images – without consent or compensation to the original artists – for use by AI companies.
Stability AI is the developer of Stable Diffusion. Stability AI trained Stable Diffusion using the LAION dataset. Stability AI has also released a paid app, DreamStudio, which packages Stable Diffusion into a web interface.
DeviantArt
DeviantArt was founded in 2000 and has long since become one of the largest artist communities on the Internet.
As Simon Willison and Andy Baio have shown, thousands, possibly millions, of images in LAION were copied from DeviantArt and used to train Stable Diffusion.
Instead of standing up for its artist community by shielding them from AI training, DeviantArt decided to release a paid application, DreamUp, built on top of Stable Diffusion. In turn, a flood of AI-generated art flooded DeviantArt, displacing human artists.
When in November 2022, during a live Q&A session, members of DeviantArt’s management team, including CEO Moti Levy, failed to explain why they betrayed their art community by accepting Stable Diffusion while intentionally violating their own terms of service and policies privacy
Midjourney
Midjourney was founded in 2021 by David Holtz in San Francisco. Midjourney offers a text image generator via Discord and a web app.
Although the company positions itself as a “research lab,” Midjourney has built a large audience of paying customers who use Midjourney’s image generator professionally. Holtz says he wants Midjourney to “focus on making everything beautiful and artistic.”
To that end, Holtz admitted that Midjourney is learning from “a big chunk of the Internet.” Although, when asked about the ethics of mass copying educational images, he replied: “There are no specific laws about it.” And when Holtz was asked whether artists could be allowed to drop out of school, he replied: “We are looking into this issue. Now the task is to find out what the rules are.”
How does artificial intelligence work?
In 2020, researchers from the University of California at Berkeley improved the diffusion method in two ways:
They showed how a diffusion model can store its training images in a more compressed format without affecting its ability to reconstruct high-fidelity copies. These compressed copies of the training images are known as latent images.
The researchers discovered that these latent images can be interpolated – that is, blended mathematically – to produce new derivative images.
 The image in the red frame was interpolated from the two “source” images pixel by pixel. It looks like two translucent images of a face superimposed on each other, rather than a single convincing face.
The image in the red frame was interpolated from the two “source” images pixel by pixel. It looks like two translucent images of a face superimposed on each other, rather than a single convincing face.
The image in the green frame was generated differently. In this case, the two original images were compressed into latent images. After these latent images were interpolated, this new interpolated latent image was reconstructed pixel by pixel using a smoothing process. Compared to pixel-by-pixel interpolation, the advantage is obvious: latent image-based interpolation looks like a single, convincing human face, rather than an overlay of two faces.
Despite the difference in results, from a copyright perspective, these two interpolation methods are equivalent: they both create derivative works by interpolating two original images.
Already in 2022, researchers from Munich have improved the diffusion technique. They figured out how to control the discoloration process with additional information. This process is called conditioning. (One of these researchers, Robin Rombach, currently works at Stability AI as a Stable Diffusion developer).
The most common learning tool is short text descriptions, also known as text prompts, that describe elements of the image, such as “dog in a baseball cap eating ice cream.” This gave birth to the dominant interface of Stable Diffusion and other AI image generators: turning a text prompt into an image.
However, the text prompt interface has another purpose. It creates a layer of magical disorientation that makes it difficult (though not impossible) for users to find obvious copies of training images. However, since all visual information in the system is derived from copyrighted training images, the generated images – regardless of appearance – are necessarily works derived from these training images.
Stories of authors affected by artificial intelligence

Image from Sarah Andersen’s public account https://www.instagram.com/ sarahandersencomics/
Sarah Andersen
Sarah Andersen is a cartoonist and illustrator. She graduated from the Maryland Institute College of Art in 2014. Now lives in Portland, Oregon. Her semi-autobiographical comic “Sarah’s Scribbles” finds humor in the life of an introvert. Her graphic novel FANGS was nominated for an Eisner Award.
Sarah also wrote the book “Alt-Right Manipulated My Comic”. Then A.I. Claimed It for the New York Times.

Image from Kelly McKernan’s public account https://www.instagram.com/ kelly_mckernan/
Kelly McKernan
Kelly McKernan is an independent artist from Nashville. She graduated from Kennesaw State University in 2009 and has been a full-time artist since 2012. Kelly creates original watercolor and acrylic gouache paintings for galleries, private commissions and an online store. In addition to having a large following on social media, Kelly shares tutorials and workshops, travels the US to events and comic conventions, and creates illustrations for books, comics, games, and more.

Ultimum, 30 x 40, oil, Chimerical, Spoke Art Gallery, 2016 http://www.karlaortizart.com/fine-art/
Carla Ortiz
Carla Ortiz is a Puerto Rican artist, internationally recognized and awarded with many awards. With her exceptional design sense, realistic rendering and character-driven storytelling, Carla has worked on many big-budget projects in the film, television and video game industries. Carla is also a regular illustrator for major publishers and RPG companies.
Carla’s figurative and enigmatic art has been featured in such notable galleries as Spoke Art and Hashimoto Contemporary in San Francisco, Nucleus Gallery, Thinkspace and Maxwell Alexander Gallery in Los Angeles, and Galerie Arludik in Paris. She currently lives in San Francisco with her cat Buddy.
artificial intelligence / claim / copyright / intellectual property


